Introduction
In the previous post, we explored integrating Snowflake with AWS, specifically focusing on loading files from S3 into Snowflake. The data was left in a staging table. This time, we’ll take the next step by moving the data into structured tables. We’ll build a data pipeline that leverages streams and tasks to transform the data as needed.
A Bit on Architectural Decisions
Before diving into the implementation, let’s discuss the different ways to access data in an external stage and consider various use cases for data pipelines. What we are building here is a continuous pipeline to extract data from S3 and load it into Snowflake. The article assumes this is a batch pipeline, but other strategies might be more appropriate for different use cases.
For example, if you need to analyze data in real time, using an external table might be more suitable. External tables allow you to query data from the external stage as if it were stored in Snowflake tables. For data validation and complex transformations, a stored procedure is an effective way to apply business logic to validate and transform the data. In this batch load pipeline, I chose to start with the data in a staging table because it is faster than querying external tables. Snowflake’s multiple methods for building transformation pipelines make it a versatile cloud-native data warehouse.
The usual suspects lineup
Before we dive into the pipeline as if it were a pool toboggan, let’s meet some of the Snowflake features we’ll be using.
Streams
Streams are a way to keep track of changes in a table or view, allowing us to continuously ingest data and focus only on the changes we want to track. Streams come in various types, such as “append” streams that track only inserts or “standard” streams that track all changes. We can also specify whether to track table changes from the beginning of time or from the current state when the stream is created. You can learn more in the Snowflake documentation.
Tasks
Tasks are functions that automate business processes. They can be scheduled or executed manually. A task can execute an SQL statement, call a stored procedure, or use Snowflake Scripting. Tasks also behave as DAGs (Directed Acyclic Graphs), meaning they can call a sequence of tasks linearly without looping back to previous tasks. The calling task is the parent task, and the subsequent tasks are children. To learn more about tasks, please refer to the Snowflake documentation.
Transformation Pipeline
The data is stored in the staging table in JSON format. Let’s revisit the diagram from the previous post to refresh our memories on how the data got there.
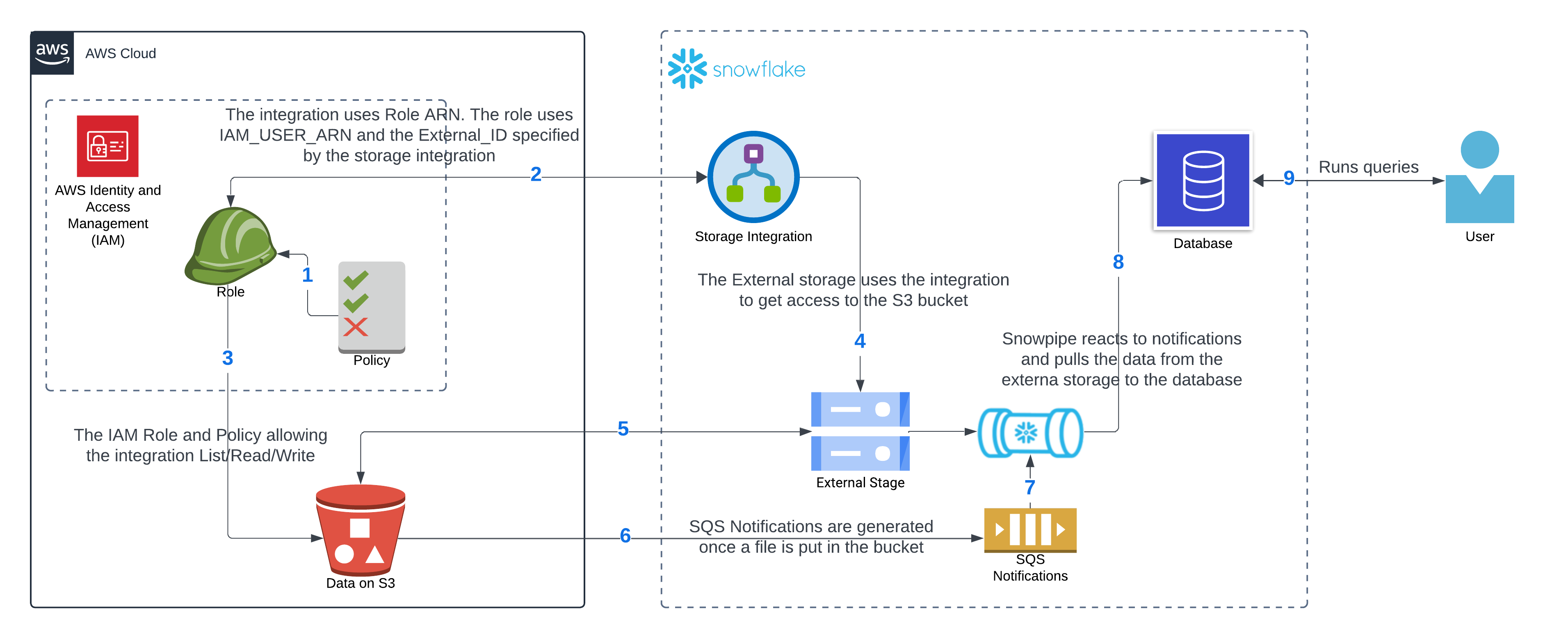
Next, we’ll zoom in on the “database” part of the diagram, focusing on the transformation pipeline and omitting the security details covered earlier. This is the diagram of the pipeline:
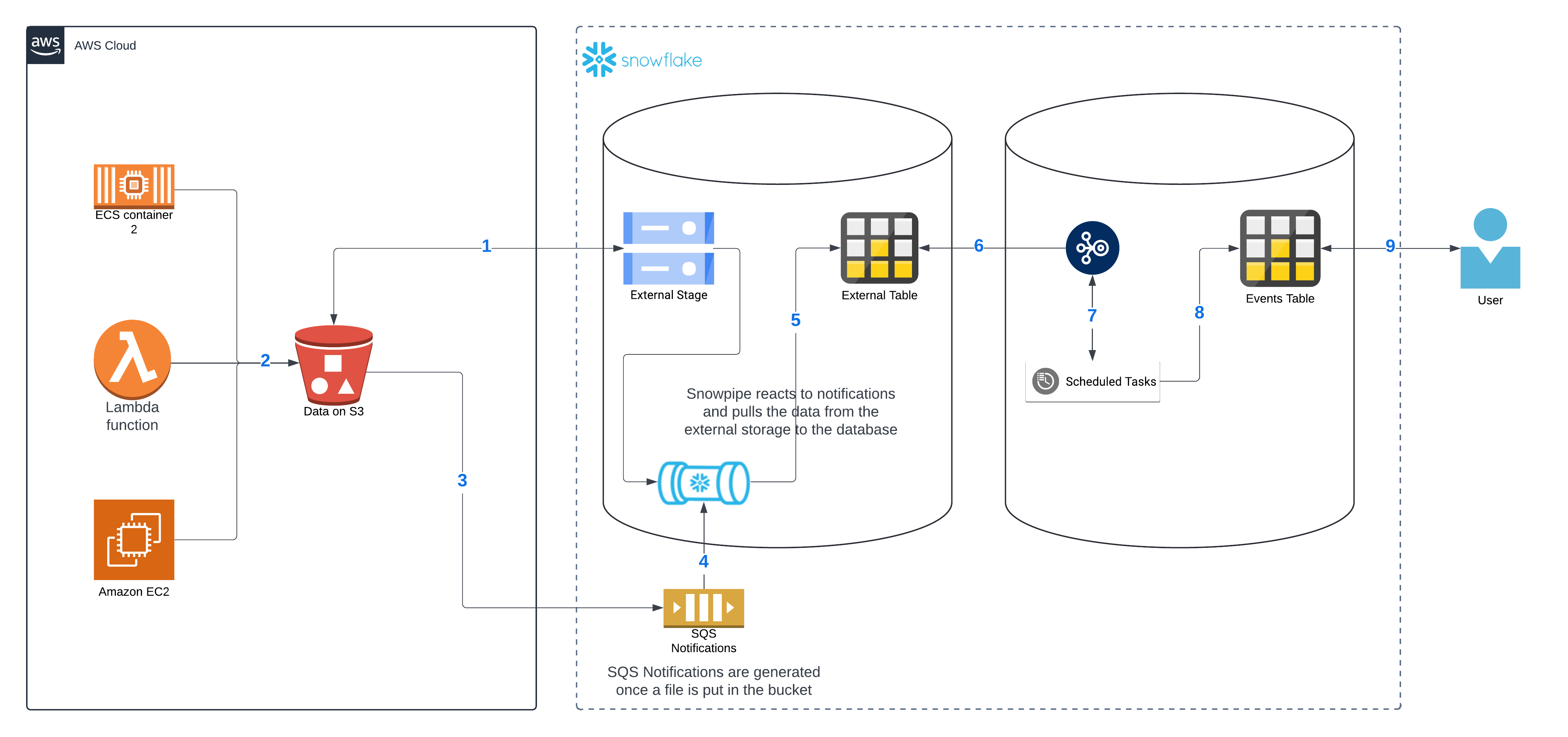
The external stage is connected to S3, where the data—whether structured, unstructured, or semi-structured—gets stored. In our example, we are using semi-structured data in the JSON format. The Snowpipe is listening to events from the SQS, which are triggered by a file being dropped in S3. The Snowpipe uses a query with the COPY INTO command to import the data from that file into our staging table.
As the data gets inserted into our staging table, the stream captures the changes in our “raw” table. The task, which runs on a schedule every 10 minutes, takes the JSON data and splits it into the appropriate fields in the target table. At this point, the user has a table with the details that matter.
Let’s get our hands dirty
I expand the previous project to create the additional objects needed. We don’t need a new database and schema; however, it makes sense to keep your “raw” data separate from your transformed data. You may end up creating multiple databases, or you may decide to keep it all in one. That decision will depend on the scale of what you’re doing and how it makes sense for you to organize your data. For this exercise, I’ll create a new database and schema to place the transformed data. We’ll then create a new table, stream, and task.
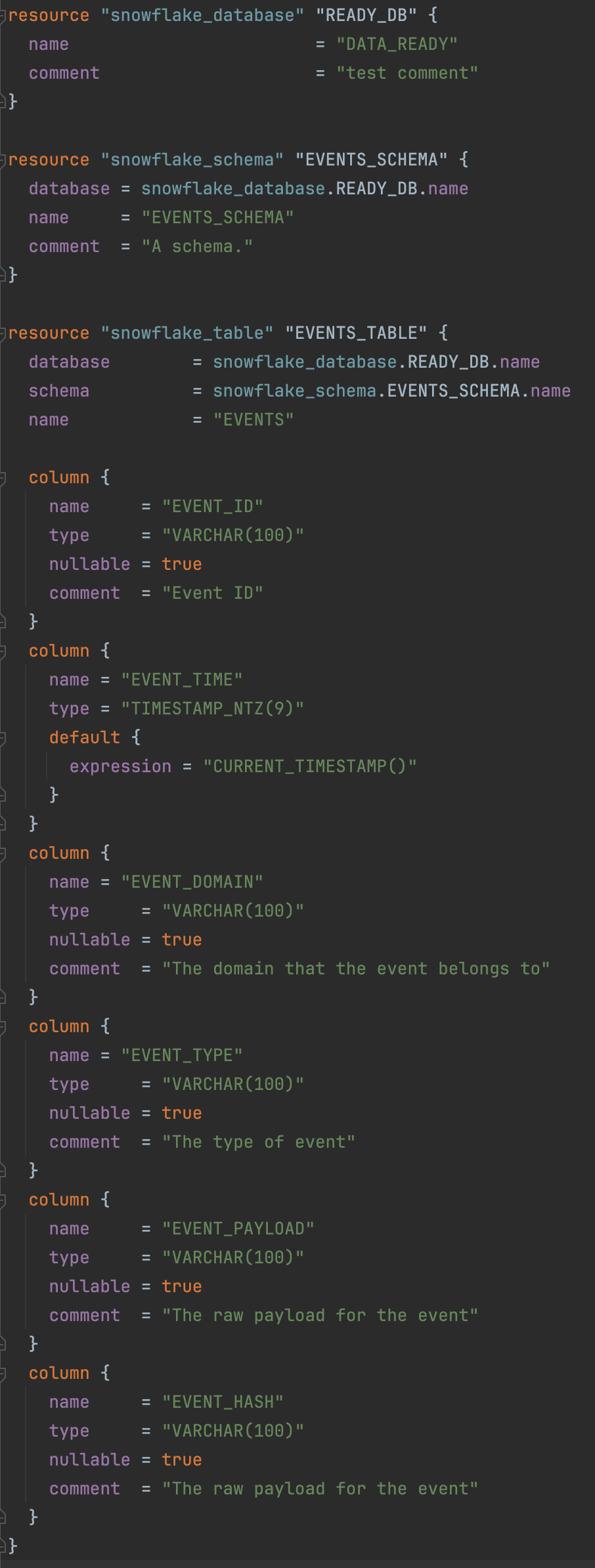
This is the Terraform code to create the new database, schema, and table:
This is a sample event:
{
"eventId": "20563168486460372286800059",
"eventPayload": "En un lugar de la mancha de cuyo nombre no puedo acordarme.",
"eventTime": "2023-05-23T13:56:43-04:00",
"eventType": "testing.LiteraturaEspanola"
}
As you can see, the table we created has more fields than the event has JSON elements. I’ll add some code to the task to parse the Event Domain (the first part of Event Type, before the period) and the Event Type (the string after the period). I’ll also add some code to generate the MD5 hash from the Event Payload. These are simple demonstrations of what can be achieved with Snowflake tasks.
This is the Terraform script to create the task and the stream:
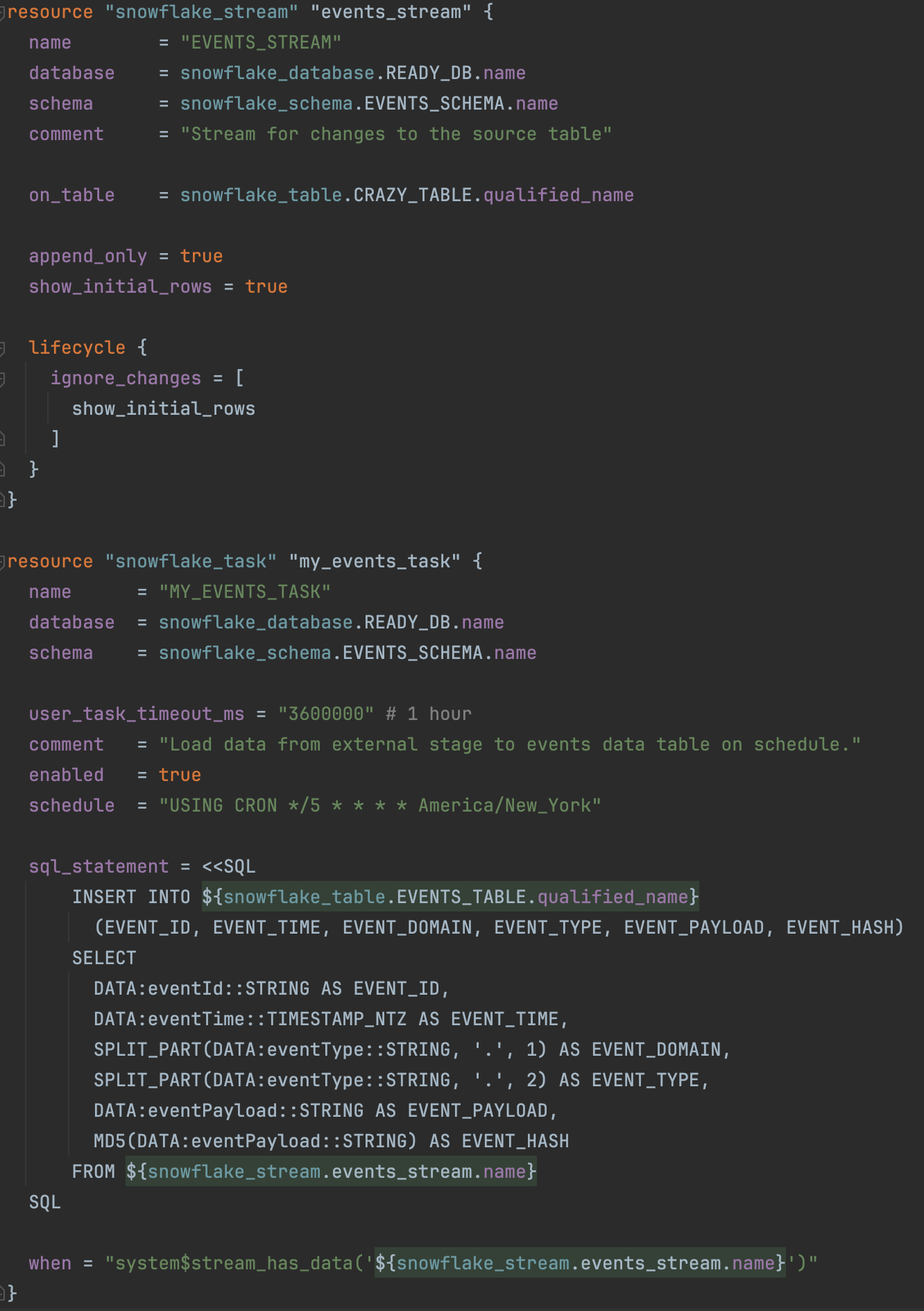
The script above creates a stream that tracks changes in the staging table. It also creates a task scheduled to run every 5 minutes. This task will execute the query to populate the events table. Notice how it accesses the data from the JSON document, splits one of the elements, and generates the MD5 hash for us. Keep in mind that this query will only run on records inserted since the last time it ran, as the stream keeps track of the records that have been consumed. The stream is set up with “show_initial_rows” set to true, meaning that the first time it is consumed, it will provide records from the beginning of time. If this property is false, only records inserted after the creation of the stream will be available.
Notice that we didn’t add a warehouse to the task, making the task serverless. This means Snowflake will choose the appropriate warehouse size internally and dynamically adjust as the task runs.
Looking At The Results
The script is ready, and all we need to do is run Terraform. Running the “terraform apply” command will create all the infrastructure mentioned above. If you have any doubts about running Terraform or the prerequisites needed for this project, you can refer to the previous post or the GitHub repository README.md file, which also discusses dependencies.
After the Terraform script is run, this is what the new items in Snowflake will look like:
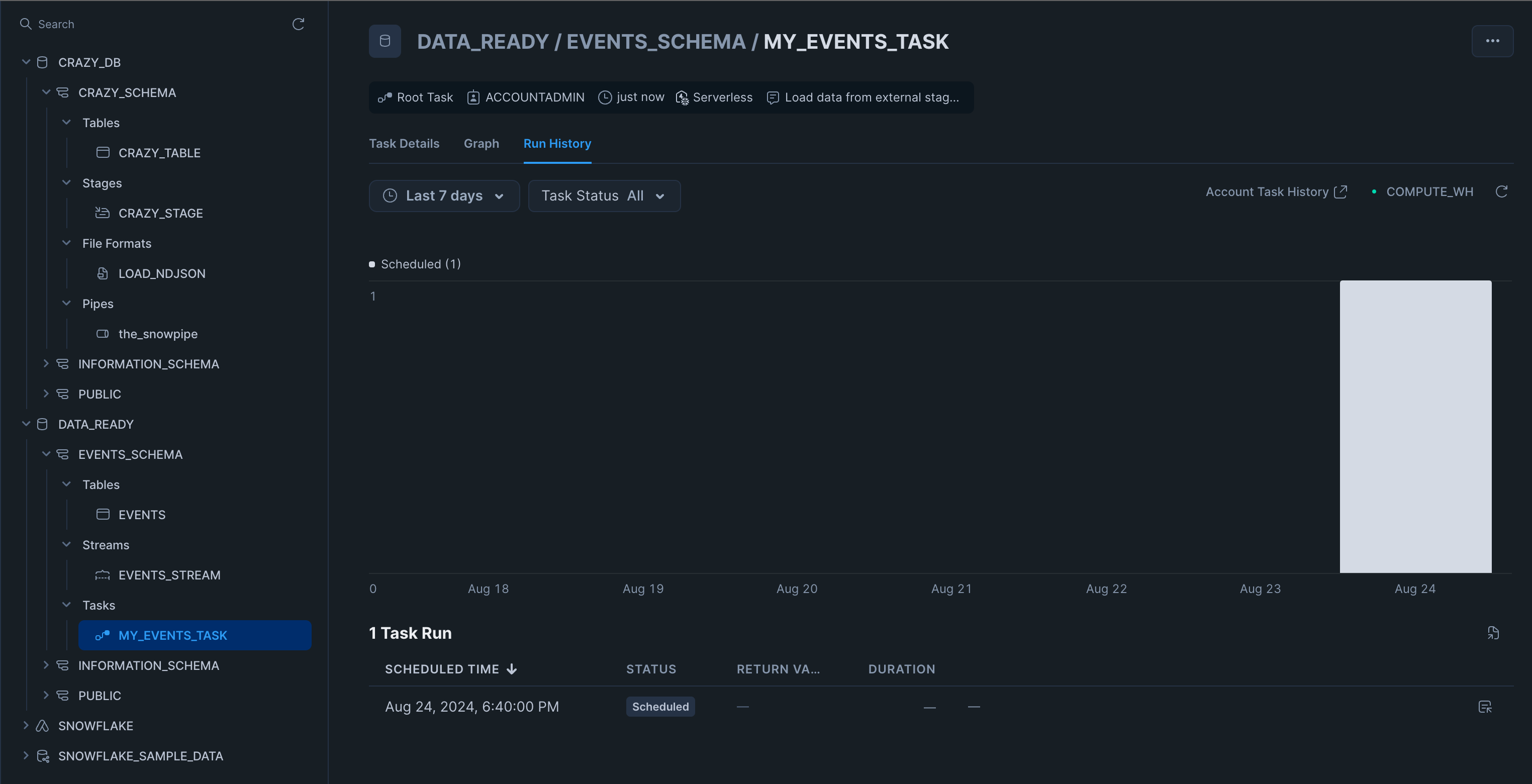
You can see the new database, the schema, the events table, the stream, and the task. The previous infrastructure is still intact. Notice how the task is scheduled to run but has never run before. In the image below, you can see the task ran once successfully, which populated our table, but the next time around, there were no records in the stream, so it was skipped. If there is no data in the stream, Snowflake skips the run without using compute resources.
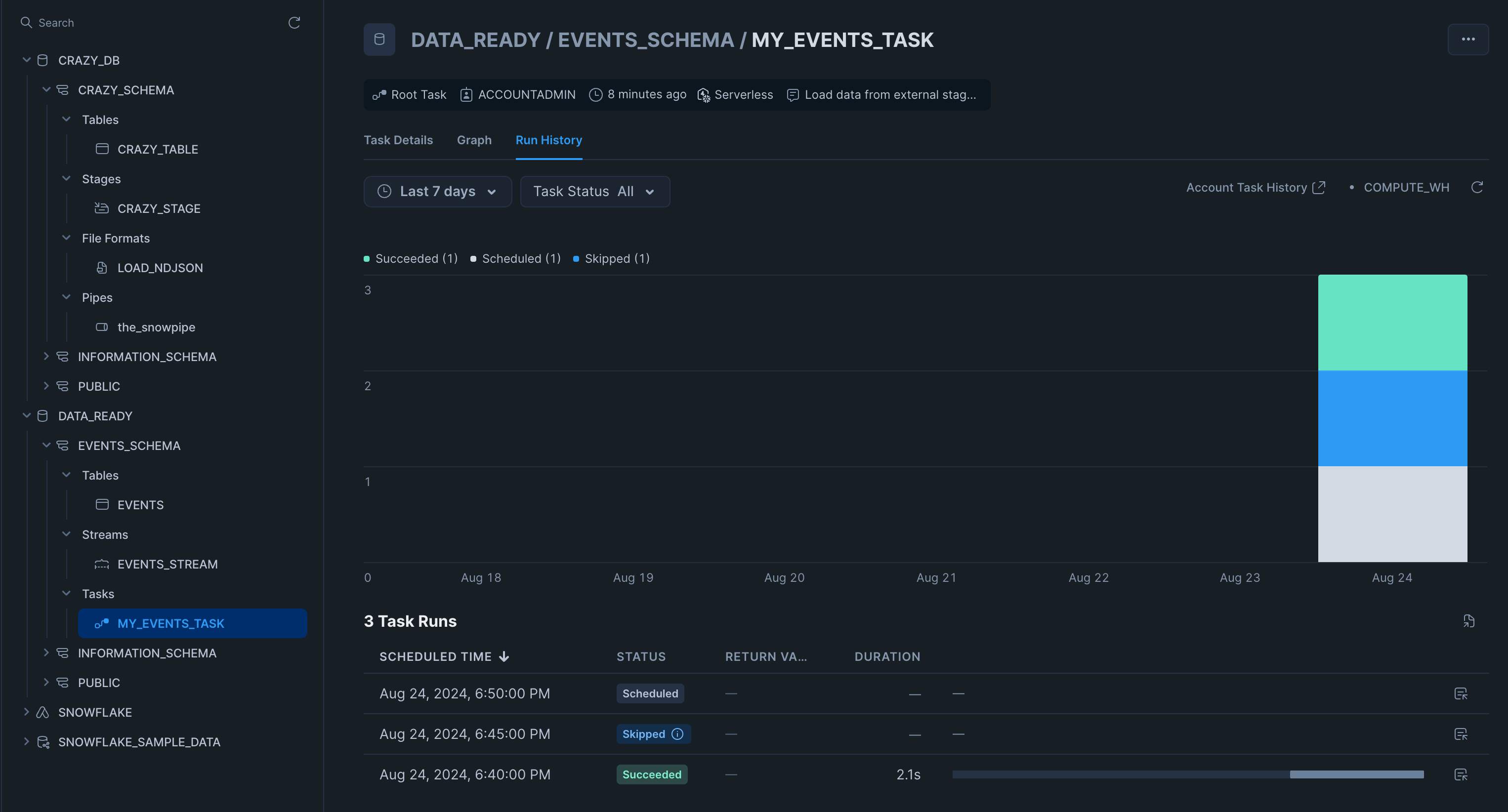
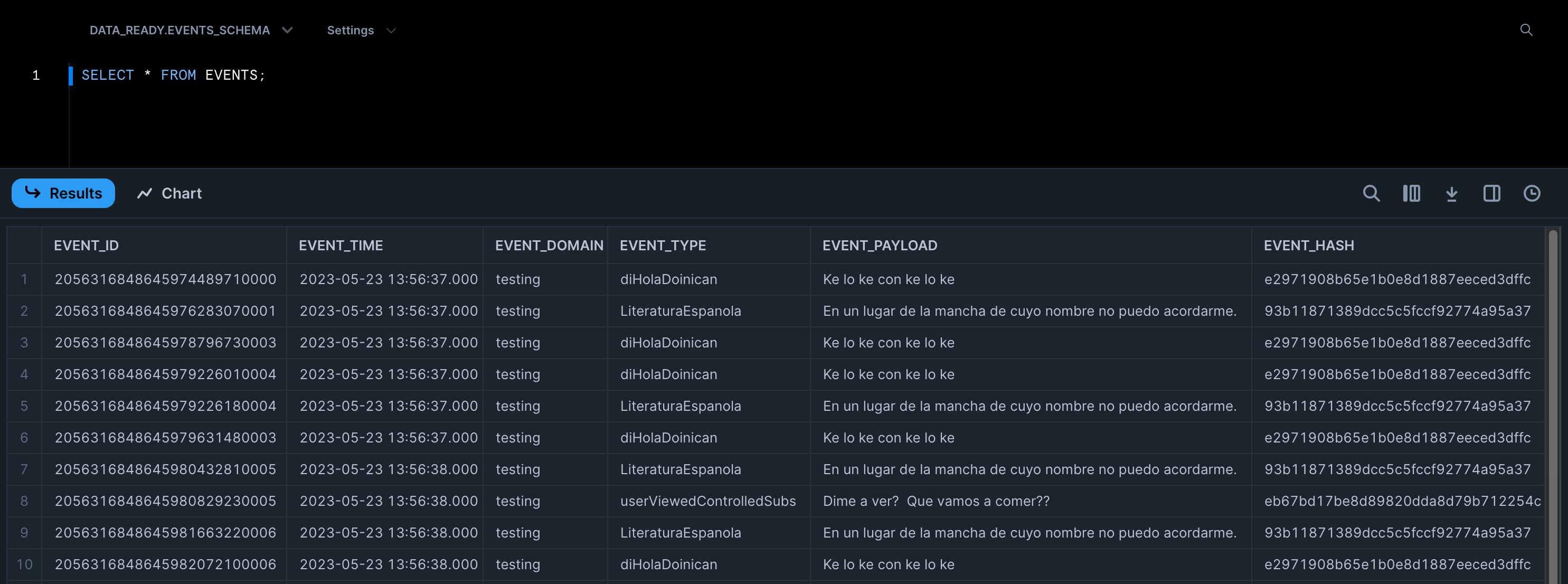
Now that the task has run, we should have data in the table. Let’s go ahead and perform a query:
Conclusion
This post demonstrated how to transform data in Snowflake. This simple example highlights Snowflake’s capabilities and offers a glimpse into the wide array of possibilities it presents. In the end, there is no one-size-fits-all recipe, and having versatile tools that allow you to adapt to different use cases is invaluable.