Introduction
My team and I were driving a project to move all the systems in an on-premises data center into the AWS cloud. The hardware on premises was approaching end of life, and it did not make sense to invest in new hardware given our company’s cloud initiative. We had a tight deadline to move said systems before the renewal of the data center contract. This constraint led us to make the decision of doing the migration as a lift and shift project.
Every project of moving applications into the cloud has many challenges, especially a “lift and
shift” type of project, given the need for additional security requirements, transient instances, etc. In order to comply with all the different business and technological constraints, architectural decisions were made with careful consideration. Part of the project required us to bring in older applications, since refactoring or replacing such applications was not an option at the time of the project.
To move into AWS and keep such older applications without changes, we had to find a creative way to share a file system with heterogeneous operating systems, we have a mix of Linux and Windows operating systems.
In the on-premises setup, we have two SFTP servers that our clients use to upload files to be processed in our system and pick up their reports. The legacy application, mentioned above, takes those files and performs tasks such as unzipping, decryption, and more. Then, it moves the file to the processing engine.
The physical structure on the SFTP mailbox is different than the structure seen by the application. Here is a sample of how the structures differ:

The SFTP side structure is more oriented towards the customer and ensuring all their mailbox folders are together. The application view of the file system is more focused on having all the folders of the same kind together for all clients since the same file types follow similar processing paths. The first step was to determine which file system would meet our needs and minimize problems. The AWS recommendation was to use the Amazon FSx file system since it can be easily mounted on both Linux and Windows. Amazon FSx does the job well and we have not had issues mounting it or using they file system as a shared file system; however, Amazon FSx has shortcomings that affected some of the decisions we had to make. For example, Amazon FSx for NetApp ONTAP supports symbolic links, but this service was not available when we were deploying production environment. Our system was heavily dependent on symbolic links as illustrated above. Amazon FSx cannot be used from AWS Lambda functions. The problem we were trying to tackle was the communication layer, which was driven by an SFTP software, had a different mailbox structure than the legacy software which picked up the files from the mailbox. We also needed a new, more robust SFTP solution while keeping our user’s credentials and our legacy software in place. Once we are in AWS, the legacy software will be removed for a more cloud native solution. In the meantime, we needed a solution that did not require us to write new code.
Methods
On premises, the file system is presented “as needed” to each application using symbolic links as shown above. To replace our SFTP Servers, we leveraged the AWS Transfer Family service. Transfer Family is a managed SFTP service which can do SFTP and FTPS. One instance of the Transfer Family service allows 10K concurrent connections. Authentication is done by using a Lambda function behind Amazon API Gateway. The Lambda function queries an LDAP directory and returns the user’s home directory if the user has valid credentials. There are multiple ways to configure the Transfer Family. One of choices we made was locking the user to their home directory. They can only see subdirectories under their home directory and cannot navigate away from it. This allows for security of the rest of the mailbox. In short, by using the AWS Transfer Family, we were able to replace our on-premises infrastructure without any new code in a secure cost-efficient fashion. The Transfer Family uses Amazon Simple Storage Service (Amazon S3) buckets as the destination for the files. The files are secure (as data is encrypted at rest on the S3 buckets). Bucket Versioning is enabled, and Lifecycle rules are applied to archive the files or delete them after a specified period of time. To solve the difference in file system structure between the SFTP mailbox structure and the legacy file system mailbox structure, we leveraged AWS Lambda and Amazon S3 File Storage Gateway. We configured Lambda functions to listen to events on the Amazon S3 bucket for the SFTP mailbox (which had a structure similar to the left side of the image above). These Lambda functions trigger on the PUT event and transform the path as necessary. The function then moves the files from the SFTP mailbox into another bucket and make the object’s prefix look like the legacy application needs it. Since we cannot modify the legacy application to read files from Amazon S3, we had to come up with another creative solution. We leveraged another AWS service, the File Storage Gateway. The File Storage Gateway gave us the ability to make an S3 bucket look like a Windows file system, so we were able to expose the S3 bucket to the application with no custom code. The design looks like this:
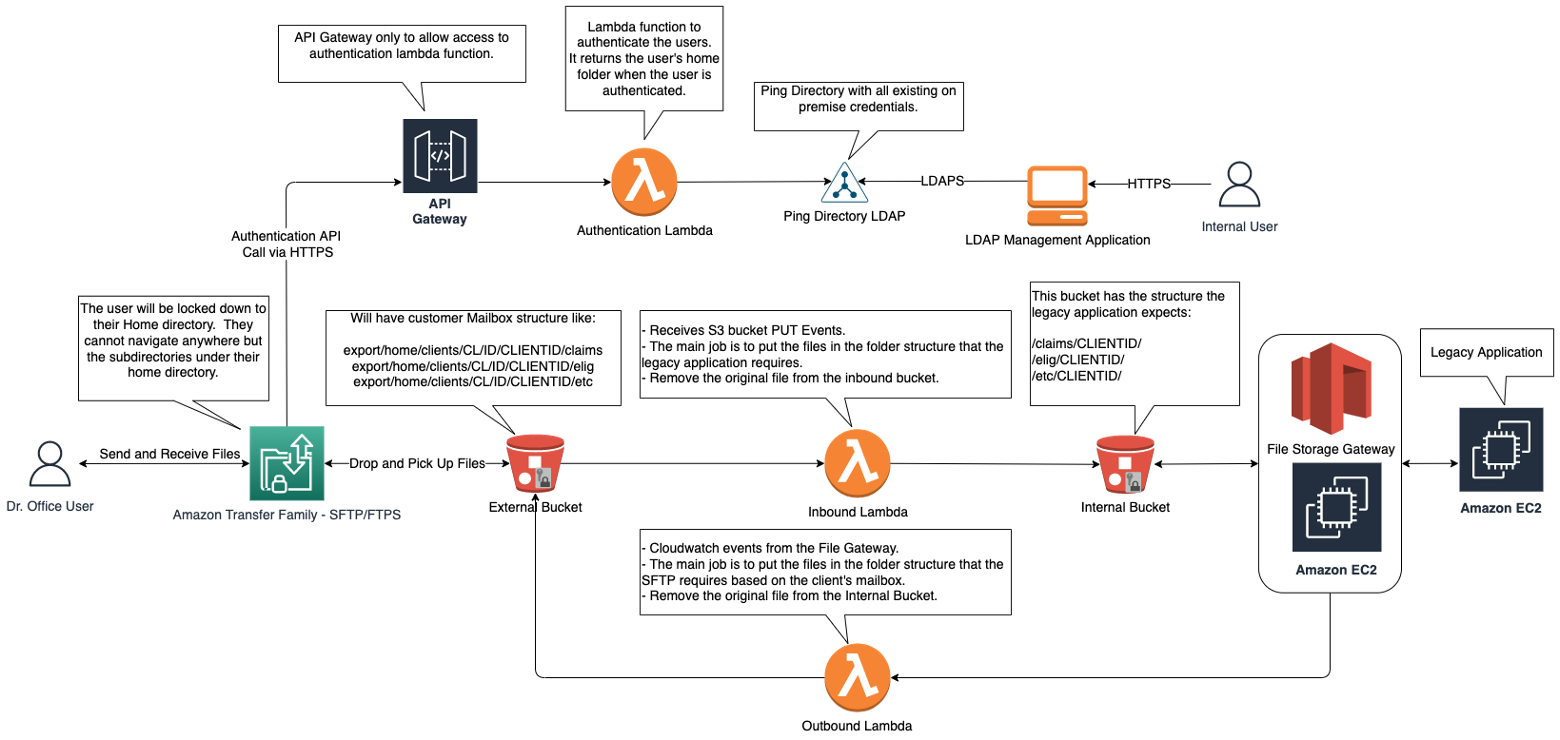
To send back the reports to the customer, we also leverage AWS Lambda; however, this time the events were configured via Amazon EventBridge Rule for AWS Storage Gateway file upload. This time, the Lambda function will do the opposite, making the prefix look as expected by the destination bucket and moving the file. Each Lambda function was configured with an Amazon Simple Queue Service (Amazon SQS) Dead letter queue for failed messages which gives us the ability to keep these files and process them later. The solution presented above provides a secure and scalable architecture without having to make any changes to the existing application. We wrote minimal code in the Lambda functions to transform the path and kept our customers credentials the same by migrating the LDAP data from on premises. We used the LDAP data as the authentication source for the AWS Transfer Family service.
Lessons Learned
While setting up this architecture, we had to experiment and test multiple settings and options, such as the configuration for the Storage Gateway so the application can perform accordingly. We also changed the File Gateway EBS volumes from GP2 to Provisioned IOPS volumes. This gave us much better performance which met the application’s expectations. Originally, we started using S3 events for both inbound and outbound files, but we had issues with outbound files as they were stored directly in the Gateway, and we were using S3 events to trigger the Lambda function. When a file is written to the Amazon S3 File Gateway, the Amazon S3 File Gateway uploads the file’s data to Amazon S3 followed by its metadata, (ownerships, timestamps, etc.). Uploading the file data creates an Amazon S3 object and uploading the metadata for the file updates the metadata for the Amazon S3 object. This process creates another version of the object, resulting in two versions of an object, causing Lambda events to fire more than once. We avoided this issue by using an Amazon EventBridge Rule for AWS Storage Gateway file upload instead of S3 events. We also had to resolve issues with the Amazon File Storage Gateway cache refresh. The S3 File Gateway needs to be refreshed when operations happen directly via S3 since the gateway is not immediately aware of changes happening outside the File Gateway’s domain. We were doing refreshes for every top folder mailbox that received a file. The idea was that files were immediately available, however, this approach was overwhelming the File Storage Gateway and causing the refresh not to work. This meant the legacy application could not see the files in the File Storage Gateway, so it was not able to process them. Rather than have the Lambda functions refresh the cache, we opted to use scheduled refreshes instead. The PUT event was only configured for files coming in from the Transfer Family; however, we ended up configuring Copy and Multipart upload completed in addition to the PUT event as large files are automatically uploaded using S3 Multipart upload and it was not triggering the Lambda function. Something to keep in mind when using the AWS Transfer Family is that it does not support DSS keys, it only support RSA keys. This would only be a problem if your customers still require using DSS keys.
Next Steps
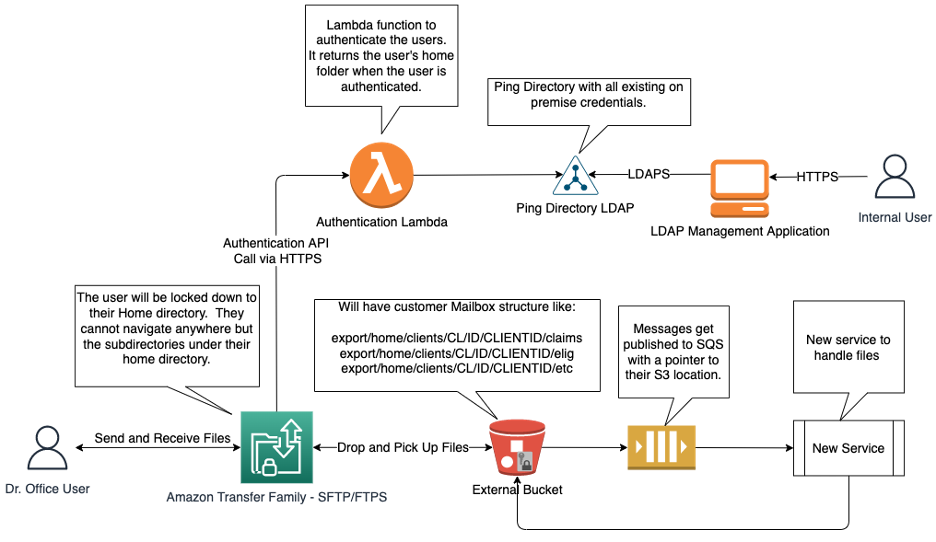
Once we remove the legacy system, we are able to move into a more cloud native application. The files can be added to an SQS queue with a reference to their S3 location for another service to consume them. We can keep some of the existing pieces in place (e.g., the Transfer Family), but others will be removed (e.g., Lambdas). Most of these changes, once again, will not require code changes, only configuration. The new services will need to be written, but that is part of the modernization effort. The Transfer Family now supports using Lambda directly for authentication. This means we can simplify the design by removing the API Gateway. The new design would look something like this:
Conclusions
This is an example of how versatile all the AWS managed services are, without going into the advantages of cloud computing, for companies that decide to migrate into the cloud. All the boiler plate code is written, and one must test the configurations to fit the needs of the organization. We were able to use several services to bridge gaps between cloud services and very old applications. This ability gave us the opportunity to move to AWS and not have to wait for all applications to be refactored. Using this approach, we replaced 3 physical servers with the AWS Transfer Family managed service which means we have less infrastructure to manage, and we get even more concurrent connections with the ability to increase the number of connections as necessary. Replacing our applications would have taken a significant amount of time, six months to a year, at least. This approach took a few weeks to build, test and validate. Not to mention that replacing the applications would have brought a significant amount of risk. New applications always have the potential to introduce problems once exposed to production traffic. By leveraging a mix of AWS services, we reduced the risk and lowered the time to complete the migration. Lift and shift migrations bring a higher cost in the cloud than refactoring applications to be cloud native. In our case, the cost of the migration even as a lift and shift end up being lower than on premises. Now, we can start the refactor process and can lower the cost. We have multiple other ways to reduce the cost, not only by refactoring to a more cloud native architecture such as leveraging serverless architectures, but we also can purchase reserve instances to lower cost. We can script lower environments to only run as needed and not 24/7. These are all cost-effective measures that we can now leverage.